In cloud computing, one key feature is to evacuate or migrate running VM instances to other nodes of the same cluster so HW/SW upgrade or maintenance operations (including powering off) can be carried out without service interruption. Those who embrace OpenStack + Nova can have some fine-grained abilities of transitioning virtual machines under various conditions when the computing node is down, when one or more instances are in stopped states or when instances are still running. Details of explanations can be found in the manpage of Nova
- host-evacuate
- host-evacuate-live
- host-server-migrate
- live-migration
- migrate
As the title indicates we are mostly interested in host-evacuate-live, which migrates all running instances to other computing nodes. This action is also more demanding so if it works, other similar actions would work with no doubts. Let’s have a look at an example when migration failed and how to fix it.
We began with a cluster of 3 control-converged nodes, cc1, cc2 and cc3, respectively. All VM instances were active and running.
 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
And tried to move all running instances on cc2 to cc3
# nova host-evacuate-live cc2
Note the status has changed from ACTIVE to MIGRATING
 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
A few seconds passed, and we saw some good news that two instances were successfully moved to cc3.
 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
Waiting for long enough, we ended up having an instance in ERROR state. Note that most of the time all instances could be successfully migrated.
 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
Such error can be confirmed from Horizon UI.
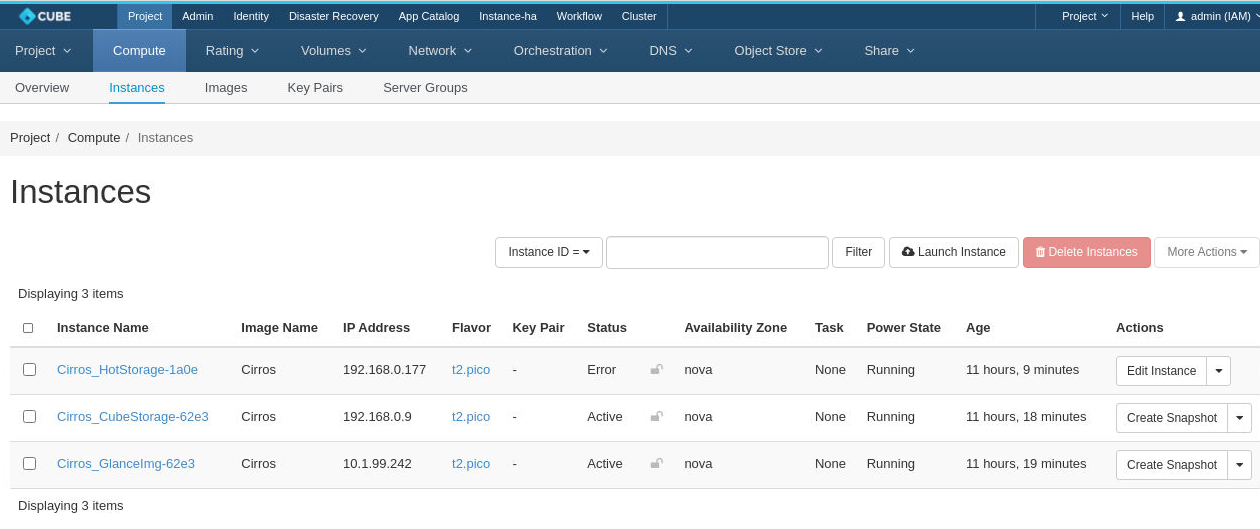 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
To diagnose what went wrong, I started out by checking logs. After checking logs in nova-compute.log on node cc2 where migration originated, I found this.
Live migration failed.: libvirt.libvirtError: Timed out during operation: cannot acquire state change lock (held by monitor=remoteDispatchDomainGetobStats)
Also checked libvirtd log on the destination node cc3. Similar error was logged.
cc3 libvirtd[39220]: Timed out during operation: cannot acquire state change lock (held by monitor=remoteDispatchDomainMigratePrepare3Params)
As CubeOS is Linux-based and the underlying full virtualization technology is KVM hypervisor, digging further down means to investigate the qmeu processes. On node cc2 there indeed was a running qemu process that matches our error instance to a T.
# ps awx | grep qemu
635175 ? Sl 51:20 /usr/libexec/qemu-kvm -name guest=instance-00000007,debug-threads=on -S
# virsh list
Id Name State
----------------------------------
2 instance-00000007 paused
A paused state was not an expected state so I would like to connect to qemu monitor to find out more.
# virsh qemu-monitor-command --hmp 2 info status
Interestingly enough, this command hung and yet it explained why logs showed timed out operations. VNC console did not respond, either. The process appeared running but for some reason was in a stoned condition. Some old posts on Internet implied some race condition among qemu threads. The gdb/gstack dumps sort of matched what others have observed. Thanks to libvirt and its buddy, virsh,, the configurations of VMs are well-tracked in xml files. This means we can safely kill the unresponsive process and spawn a brand new one with exact setup.
# virsh destroy 2
Domain '2' destroyed
# virsh list --all
Id Name State
------------------------------------
- instance-00000007 shut off
And indeed, the old qemu process was killed.
# ps awx | grep qemu
3633296 pts/2 S+ 0:00 grep --color=auto qemu
# virsh start instance-00000007
Domain 'instance-00000007' started
# virsh list
Id Name State
-----------------------------------
4 instance-00000007 running
# virsh qemu-monitor-command --hmp 4 info status
VM status: running
# virsh console 4
Connected to domain 'instance-00000007'
Escape character is ^] (Ctrl + ])
login as 'cirros' user. default password: 'gocubsgo'. use 'sudo' for root.
cirros-hotstorage-1a0e login: cirros
cirros
Password:
$ hostname
hostname
cirros-hotstorage-1a0e
$ uptime
uptime
19:25:08 up 12:03, 1 users, load average: 0.00, 0.00, 0.00
$
This was almost the end except for one extra step to notify OpenStack that the state of the instance was actually healthy.
# openstack server set --state active 198e7b81-8267-44dc-a061-0cf63a970e57
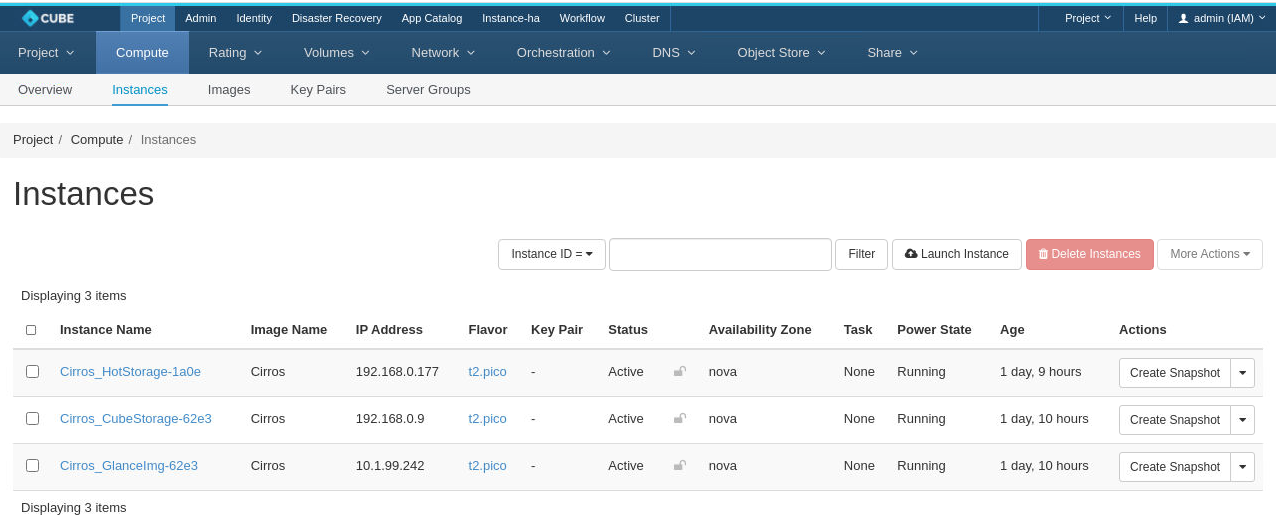 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
All was well again but I still needed to run the evacuation command one more time to move the revived instance that was still on cc2 to cc3.
# nova host-evacuate-live cc2
We could also connect to the more user-friendly UI console to interact with newly-migrated VM.
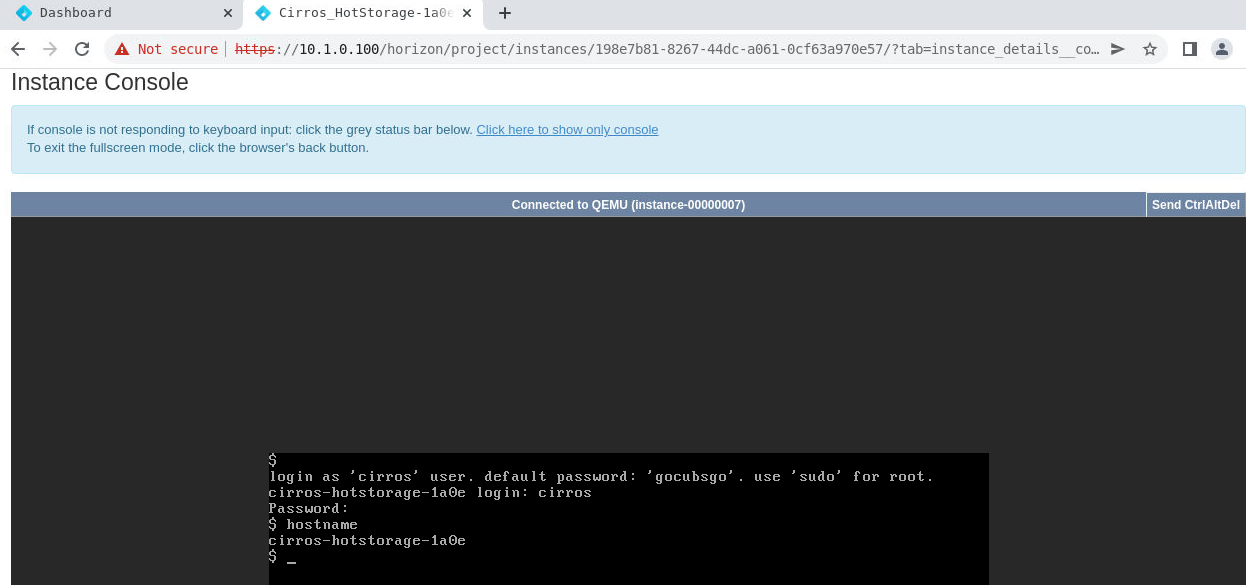 Image Source : Bigstack CubeOS
Image Source : Bigstack CubeOS
After all these, node cc2 was empty (no VM instances) and ready for maintenance operations.

